BLOGG
Vad är en CMDB: En heltäckande guide till Configuration Management Database
Konfigurationshanteringsdatabasen (Configuration Management Database, eller kort CMDB) är en avgörande komponent inom IT Service Management (ITSM). Den fungerar som ett centralt arkiv för att lagra och hantera information om olika konfigurationsenheter (Configuration Items, eller kort CIs) inom en organisations IT-infrastruktur. I denna guide fördjupar vi oss i grunderna inom CMDB, dess huvudelement, dess roll inom ITSM, processen för att implementera den och bästa praxis för att hantera den effektivt.
Grunderna i en CMDB
Innan vi går vidare, låt oss definiera vad exakt en CMDB är och förstå dess betydelse i kontexten av IT.
En CMDB är en databas som innehåller information om alla konfigurationsenheter (CIs) som är avgörande för en organisations IT-infrastruktur. Den ger en detaljerad uppgift om dessa CIs, inklusive deras egenskaper, relationer och annan relevant information.
En CMDB fungerar som ett centraliserat arkiv för att hantera och spåra konfigurationsenheter inom en organisation. Den agerar som en enda sanning, vilket säkerställer att korrekt och uppdaterad information om IT-tillgångarna är lätt tillgänglig.
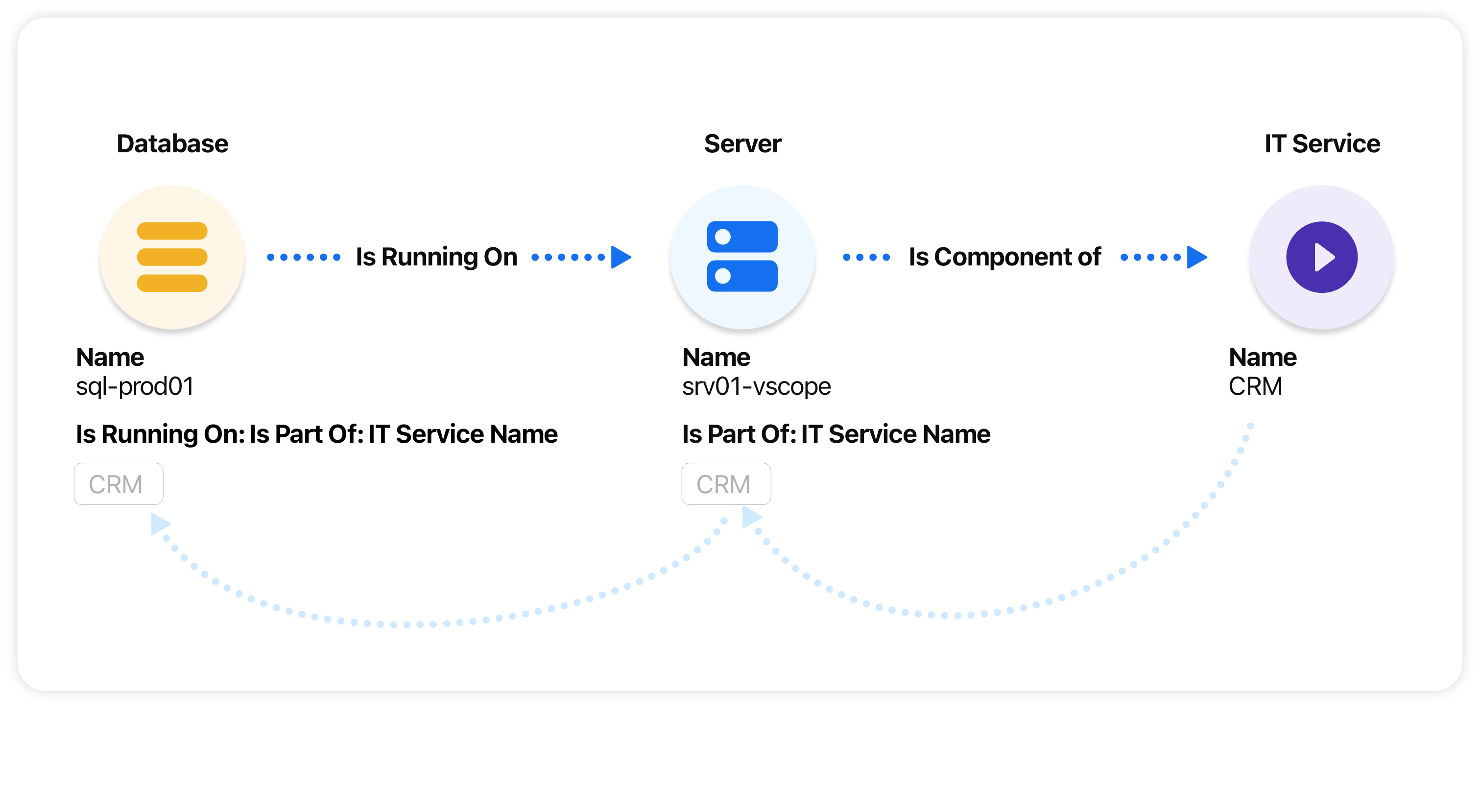
En illustration av CIs (så kallade ”Assets” i vScope) och dess relationer.
Betydelsen av en CMDB kan inte överdrivas. Den hjälper inte bara organisationer att hålla koll på sina IT-tillgångar utan fungerar också som en grund för olika IT Service Management (ITSM)-processer som incidenthantering, förändringshantering och problemhantering.
Genom att underhålla en välstrukturerad och välskött CMDB kan företag få värdefulla insikter om sin IT-infrastruktur. De kan enkelt identifiera beroenden och relationer mellan olika konfigurationsenheter, vilket gör det möjligt för dem att förstå påverkan av eventuella förändringar eller incidenter på hela systemet.
Dessutom spelar en CMDB en avgörande roll för att säkerställa efterlevnad av regelverk och branschstandarder. Den hjälper organisationer att visa kontroll över sina IT-tillgångar och ger en tydlig revisionslogg för alla ändringar som görs på konfigurationsenheterna.
Med hjälp av en CMDB kan organisationer effektivisera sina processer för IT-tjänstleverans. De kan snabbt identifiera roten till incidenter, följa framstegen för förändringar och proaktivt hantera potentiella problem. Detta förbättrar inte bara effektiviteten i IT-driften utan ökar också den övergripande kvaliteten på tjänsterna som erbjuds till användarna.
Dessutom underlättar en CMDB effektivt beslutsfattande genom att tillhandahålla korrekt och tillförlitlig information. Den möjliggör för IT-chefer att bedöma påverkan av föreslagna förändringar, utvärdera riskerna som är förknippade med dem och fatta informerade beslut baserade på datadrivna insikter.
Sammanfattningsvis är en välskött CMDB en ovärderlig tillgång för varje organisation. Den ger IT-teamen möjlighet att effektivt hantera sin IT-infrastruktur, optimera tjänsteleveransen och säkerställa stabilitet och tillförlitlighet i sina system.

Huvudkomponenter i en CMDB
En Konfigurationshanteringsdatabas (CMDB) är ett avgörande verktyg för effektiv konfigurationshantering inom en organisation. Den består av olika huvudkomponenter som samverkar sömlöst för att säkerställa korrekt och aktuell information om organisationens konfigurationsenheter. Låt oss utforska dessa komponenter i detalj.
Konfigurationsenheter (CIs)
Hjärtat av en CMDB är Konfigurationsenheter (CIs). Dessa CIs fungerar som de grundläggande byggstenarna som representerar olika element inom en organisations infrastruktur. De kan inkludera en mängd olika komponenter som hårdvaruenheter, programvaruapplikationer, databaser, nätverkskomponenter och mer. Varje CI tilldelas en unik identifierare, vilket möjliggör enkel identifiering och spårning inom CMDB.
Genom att inkludera en omfattande mängd CIs kan organisationer få en holistisk vy över hela sin infrastruktur, vilket möjliggör effektiv hantering och kontroll av sina konfigurationsenheter. Detta säkerställer i sin tur att eventuella förändringar eller uppdateringar som görs på dessa enheter noggrant registreras och spåras inom CMDB.
Attribut och Relationer
Inom en CMDB är varje CI associerad med en uppsättning attribut som tillhandahåller ytterligare information om objektet. Dessa attribut kan inkludera detaljer som CIs namn, typ, version, ägare, plats och annan relevant information. Genom att fånga och underhålla dessa attribut kan organisationer få en omfattande förståelse för sina konfigurationsenheter, vilket underlättar effektivt beslutsfattande och felsökning.
Utöver attribut spelar relationer en avgörande roll i en CMDB. Relationer definierar kopplingar och beroenden mellan olika CIs. Genom att etablera och dokumentera dessa relationer kan organisationer få insikter om hur förändringar i en CI kan påverka andra. Denna kunskap är ovärderlig vid planering av förändringar eller felsökning av problem inom infrastrukturen.

Exempel på IT-tjänster som dokumenteras i vScope.
Dessutom kan relationer i en CMDB sträcka sig bortom direkta kopplingar mellan CIs. De kan även inkludera relationer med andra enheter som användare, avdelningar eller platser. Detta bredare perspektiv möjliggör för organisationer att bättre förstå påverkan av konfigurationsförändringar på olika aspekter av deras verksamhet.
Sammanfattningsvis består en CMDB av olika huvudkomponenter som samverkar harmoniskt för att säkerställa effektiv konfigurationshantering. Konfigurationsenheter (CIs) fungerar som grundläggande byggstenar, medan attribut och relationer ger den nödvändiga kontexten och kopplingarna. Genom att dra nytta av dessa komponenter kan organisationer uppnå bättre kontroll, synlighet och förståelse av sin infrastruktur, vilket leder till förbättrat beslutsfattande och operationell effektivitet.
Rollen av CMDB inom IT Service Management (ITSM)
Nu när vi har en god förståelse för grunderna, låt oss utforska hur en CMDB spelar en avgörande roll i olika IT Service Management (ITSM)-processer.
En CMDB är ett centralt arkiv som lagrar information om konfigurationsenheter (CIs) inom en organisations IT-infrastruktur. Den ger en omfattande vy över relationer och beroenden mellan dessa CIs, vilket möjliggör för organisationer att effektivt hantera sina IT-tjänster.
Incidenthantering och CMDB
Inom incidenthantering hjälper en CMDB IT-teamen att snabbt identifiera de berörda CIs och deras relationer, vilket leder till snabbare lösning av incidenter. När en incident inträffar ger CMDB värdefulla insikter om de påverkade CIs, deras associerade tjänster och beroendena mellan dem.
Till exempel, låt oss säga att en kritisk server går ner och orsakar en tjänstavbrott. Med en CMDB på plats kan IT-teamet enkelt identifiera servern, dess beroenden (som network switches och lagringsenheter) samt tjänsterna som är beroende av den. Denna information möjliggör prioritering av incidenten, effektiv resursallokering och återställning av tjänster på ett snabbt sätt.
Vidare möjliggör en CMDB för organisationer att analysera påverkan av incidenter på deras tjänster. Genom att korrelera incidentdata med CMDB-information kan IT-teamen identifiera återkommande problem, upptäcka trender och vidta proaktiva åtgärder för att förhindra framtida incidenter.
Förändringshantering och CMDB
Under förändringshantering ger en CMDB insikter om den nuvarande statusen för IT-miljön, vilket gör att organisationer kan bedöma den potentiella påverkan av förändringar och planera dem därefter. Den säkerställer att förändringar implementeras smidigt och utan oavsiktliga konsekvenser.
När en förändringsförfrågan lämnas in spelar CMDB en avgörande roll i att utvärdera påverkan av den föreslagna förändringen. Den ger en omfattande vy över de berörda CIs, deras relationer och de tjänster de stödjer. Denna information hjälper organisationer att bedöma riskerna med förändringen, bestämma nödvändiga godkännanden och resurser samt utveckla en effektiv genomförandeplan.

Till exempel, låt oss överväga ett scenario där en uppgradering av mjukvara planeras för en kritisk applikation. Genom att använda CMDB kan organisationer identifiera alla CIs som är associerade med applikationen, såsom servrar, databaser och nätverkskomponenter. De kan sedan bedöma den potentiella påverkan av uppgraderingen på dessa CIs och planera därefter, vilket säkerställer att förändringen implementeras smidigt och utan att orsaka störningar i tjänsterna.
Dessutom ger en CMDB organisationer en historisk inspelning av förändringar, vilket gör det möjligt för dem att spåra och revidera de ändringar som görs i deras IT-infrastruktur. Denna information är värdefull för efterlevnadssyften och hjälper organisationer att upprätthålla en pålitlig och säker IT-miljö.
Implementering av en CMDB
Implementering av en CMDB kräver noggrann planering och utförande. Låt oss utforska de nödvändiga stegen för att framgångsrikt implementera en CMDB.
Steg för att implementera en CMDB
Implementeringsprocessen innebär vanligtvis att identifiera omfattningen och målen för CMDB, definiera CI-taxonomin, samla in och importera initial CI-data, sätta upp den nödvändiga infrastrukturen, konfigurera CMDB-programvaran och genomföra rigorös testning innan den går live.
Vanliga Utmaningar och Lösningar
När organisationer implementerar en CMDB står de ofta inför utmaningar som datainkonsekvenser, brist på samarbete och motstånd mot förändring. Att hantera dessa utmaningar kräver korrekt datarensning, främjande av tvärfunktionellt samarbete och utbildning av intressenter om fördelarna med CMDB.

Bästa Praxis för CMDB-Hantering
Att effektivt hantera en CMDB är avgörande för att bibehålla dess noggrannhet och relevans över tiden. Här är några bästa praxis för framgångsrik CMDB-hantering.
Löpande Granskning och Städning
Regelbunden granskning av CMDB säkerställer att informationen som lagras i den är korrekt, aktuell och återspeglar den aktuella statusen för IT-miljön. Städaktiviteter innebär att identifiera och ta bort dubbla eller föråldrade poster, lösa datainkonsekvenser och utföra normalisering av data.
Integrera CMDB med Andra ITSM-Verktyg
Att integrera CMDB med andra ITSM-verktyg som incidenthantering, förändringshantering och tjänstekatalogsystem förbättrar dess funktionalitet och möjliggör för organisationer att ha en helhetsvy över sina IT-tjänster. Denna integration främjar datakonsistens, effektiviserar processer och förbättrar övergripande tjänsteleverans.
Avslutning
Sammanfattningsvis är CMDB en grundläggande komponent inom ITSM som hjälper organisationer att effektivt hantera sina IT-tillgångar. Att förstå grunderna i CMDB, dess huvudelement, dess roll i ITSM-processer, att implementera den framgångsrikt och att följa bästa praxis för CMDB-hantering är avgörande för att organisationer ska uppnå optimal tjänsteleverans och maximera värdet av sin IT-infrastruktur.
vScope tillhandahåller marknadens ledande CMDB som baserat på automatisk IT-inventering gör det enkelt att underhålla en uppdaterad dokumentation av sin IT-infrastruktur. Kontakta oss så berättar vi mer!
PUBLISHED
28 November 2023

Anton Berghult
Product Expert


Prenumerera på vårt nyhetsbrev
Låt oss hålla dig uppdaterad med nyheter och trender som hjälper dig bygga bättre samarbeten inom IT.
Learn more…

Träffa oss på Service Support i Fokus 2025
February 28, 2025 · Anton Berghult · Event Träffa oss på Service Support i Fokus 2025 Vill du veta mer hur IT Visibilitet och IT-Inventering hjälper er att skapa en mer effektiv service-funktion?
Tracker: Stenkoll på förändringar
Med Tracker får du dagliga uppdateringar och viktiga insikter i hur du håller din IT-miljö "up-to-date" och enligt branschstandards.
IT-visibilitet: Avgörande för företags effektivitet och om hur vScope stöttar med inventering
Lär dig om hur IT-visibilitet bidrar till att göra företag mer effektiva och hur vScope hjälper till med IT-inventering för ökad säkerhet, samarbeten och efterlevnad av regler.